
이번에는 이전 글들에 이어서 Streamlit을 이용한 AI 음성 생성 프로젝트를 간단히 만들어보려고 해요.
Streamlit은 파이썬으로 이루어진 프레임워크로 간단한 코드로 적당한 UI를 생성할 수 있게 해 줘요.
프론트엔드 경험이 없어도 차트나 표, 메뉴, 폼 등 간단하면서 필수적인 UI들을 쉽게 만들 수 있게 해 줘서, AI 나 머신러닝, 데이터 관련 파이썬 프로젝트들이 다수 가져다 쓰고 있는 프레임워크예요.
위처럼 간단한 코드로 csv 파일을 읽어서 차트를 그려낼 수 있어요.
제가 이번에 만들려는 AI 음성 프로젝트도 복잡한 UI 요소가 필요하지 않아서 Streamlit으로 구현해보려고 해요.
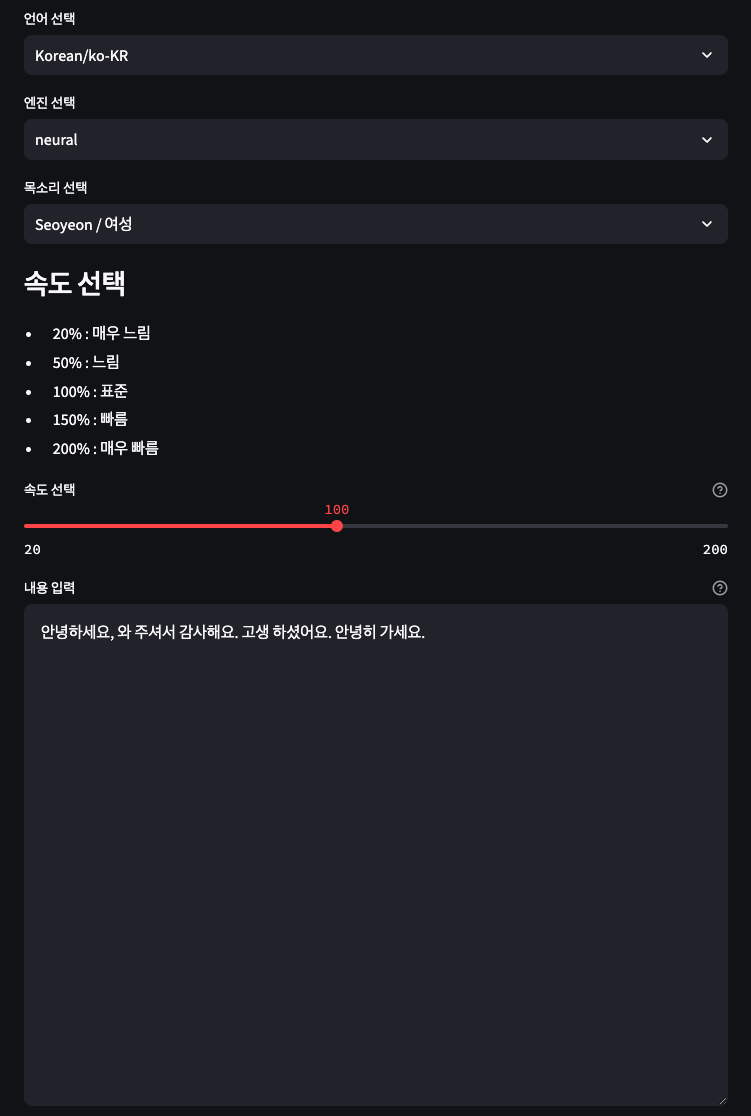
어렵지 않게 아래 정도의 UI는 뚝딱 만들어 낼 수 있어요 :)
# AI Voice Helper
먼저 음성을 합성해 주는 헬퍼를 하나 만들 건데요, 이전 글에서 한 파일 안에 구현했던 것과 달리 헬퍼로 분리했어요.
boto3 클라이언트는 AWS 서비스 전체를 호출할 때 사용할 수 있고, service_name을 제외하고는 모두 공통의 매개변수를 사용하고 있어요. 그래서 생성자를 공통으로 두고 사용하고 싶었어요.
class AIVoiceHelper:
def __init__(self, service, access_key, secret_access_key):
self.client_polly = boto3.client(
service, # cloudwatch / polly
region_name='ap-northeast-2',
aws_access_key_id=access_key,
aws_secret_access_key=secret_access_key
)
그리고 클래스 메서드로 음성 합성 요청을 구현했어요. 이전과 다르게 속도와 엔진 인자를 추가해서 음성 합성에 다양성을 줄 수 있게 했어요. 텍스트 형식도 ssml 형식을 사용했는데, 음성 합성 마크업 언어라고 불리는 형식이에요. AWS에서만 사용하는 형식은 아니고 음성 합성 기술을 사용하는 구글, 카카오, MS 등 모든 곳에서 사용하는 범용 언어예요. 구글 ssml 참고
일단은 <prosody rate> 태그로 속도에만 변화를 줘봤고요, 음성 높낮이, 쉬어가는 구간 등을 더 표현할 수도 있어요.
이 메서드에서는 boto3 클라이언트를 통해 synthesize_speech를 호출해 음성을 합성한 후 audio stream을 반환해 줘요.
스트림을 반환받은 곳에서는 이 스트림을 이용해 음성을 재생하거나 파일을 만들어 다운로드하게 해 줄 거예요.
def synthesize_voice(
self,
text,
voice_id,
rate=100,
engine="neural"
):
ssml_text = f"""
<speak>
<prosody rate="{rate}%">
{text}
</prosody>
</speak>
"""
try:
# Request speech synthesis
response = self.client_polly.synthesize_speech(
Text=ssml_text,
OutputFormat='mp3',
TextType='ssml',
VoiceId=voice_id, # You can change the voice here
Engine=engine,
)
# audio stream 으로 전달
if "AudioStream" in response:
return response['AudioStream'].read()
else:
print("AudioStream not found in the response")
return None
except Exception as e:
raise e
# voices_dict
어떤 언어, 음성, 엔진을 사용할 지에 대한 기준 데이터가 있어야 했고, AWS의 Voices in Amazon Polly에서 제공하는 데이터를 chat GPT의 도움으로 가공하여 아래처럼 dictionary를 추출해 냈어요. 이 데이터를 기준으로 UI에서 원하는 언어, 엔진, 목소리를 선택하게 해 줄 거예요.
voices_dict = {
"Arabic/arb": {
"standard": [
{
"이름": "Zeina",
"gender": "여성",
"point": None,
"select_data": "Zeina / 여성"
}
]
},
"Arabic (Gulf/ar-AE": {
"neural": [
{
"이름": "Hala",
"gender": "여성",
"point": "Bilingual",
"select_data": "Hala / 여성 / Bilingual"
},
{
"이름": "Zayd",
"gender": "남성",
"point": "Bilingual",
"select_data": "Zayd / 남성 / Bilingual"
}
]
},
...
}
# streamlit 그려내기
이제 본격적으로 UI를 그려낼 건데요, 먼저 기본 설명과 AWS key 정보를 받을 인풋 창을 만들어줍니다.
import streamlit as st
from helper.ai_voice_helper import AIVoiceHelper
from helper.voices_dictionary import voices_dict
voice_dict = voices_dict.copy()
language_list = voice_dict.keys()
st.set_page_config(
page_title="AI 음성 만들기 with AWS Polly",
page_icon="🎤",
)
st.title("AI 음성 만들기")
st.markdown(
"""
AI 음성을 만들어 보세요.
### 사용법
1. 언어를 선택 합니다.
2. 엔진을 선택 합니다.
- neural 엔진 : 표준 음성보다 더 높은 품질의 음성을 생성할 수 있습니다. NTTS 시스템은 가능한 가장 자연스럽고 인간과 유사한 텍스트 음성 변환을 제공합니다.
- standard 엔진 : 표준 TTS 음성은 연결합성(concatenative synthesis)을 사용합니다. 이 방법은 녹음된 음성의 음운을 연결하여 매우 자연스러운 합성 음성을 생성합니다. 그러나 불가피한 음성 변화와 음파를 분할하는 기술적인 한계로 인해 음성의 품질이 제한됩니다.
3. 목소리를 선택 합니다.
4. 속도를 선택 합니다.
</br>
""",
unsafe_allow_html=True
)
with st.sidebar:
access_key = st.text_input(
"Write down a AWS ACCESS KEY",
placeholder="AWS ACCESS KEY",
)
secret_access_key = st.text_input(
"Write down a AWS SECRET ACCESS KEY",
placeholder="AWS SECRET ACCESS KEY",
)
그리고 셀렉트 박스를 사용하여 이전에 불러왔던 음성 기준 데이터들을 선택할 수 있게 해 줘요.
언어, 엔진, 목소리를 선택한 후 속도를 선택해요. 속도는 polly에서 제공하는 범위 내에서만 선택할 수 있게 지정했어요.
마지막으로 음성으로 만들어 내고 싶은 텍스트를 입력해요.
selected_language = st.selectbox("언어 선택", language_list)
selected_engine = st.selectbox("엔진 선택", voice_dict[selected_language].keys())
select_data_list = [item['select_data'] for item in voice_dict[selected_language][selected_engine]]
selected_data = st.selectbox("목소리 선택", select_data_list)
selected_person_name = selected_data.split(" / ")[0] # "Lupe / Female / Bilingual" -> "Lupe"
st.markdown(
"""
### 속도 선택
- 20% : 매우 느림
- 50% : 느림
- 100% : 표준
- 150% : 빠름
- 200% : 매우 빠름
""",
unsafe_allow_html=True
)
speed_rate = st.slider(
label="속도 선택",
min_value=20, max_value=200, value=100,
help="전체적으로 적용할 속도를 선택합니다. ssml 태그를 사용하면 부분적으로 속도를 따로 적용할 수 있습니다.",
)
text = st.text_area(
label="내용 입력",
help='음성으로 변환할 내용을 입력해주세요.',
placeholder='음성으로 변환할 내용을 입력해주세요.',
height=500,
)
이제 음성 만들기라는 버튼을 이용해서 polly 에 음성 합성을 요청할 수 있게 만들어요.
만들어진 음성은 audio stream으로 가지고 있다가, st.audio를 통해 미리 듣기를 제공해요.
만들어진 음성이 마음에 들면 다운로드도 할 수 있게 st.download_button을 사용해 버튼을 만들어줬어요.
파일 이름은 선택한 언어나 목소리 등의 정보가 들어갈 수 있게 가공했어요.
create = st.button(
label="음성 만들기",
)
if create:
if selected_person_name and text:
try:
audio_stream = AIVoiceHelper(
service="polly",
access_key=access_key,
secret_access_key=secret_access_key,
).synthesize_voice(
text=text,
voice_id=selected_person_name,
rate=speed_rate,
engine=selected_engine,
)
except Exception as e:
st.error(f"음성 변환에 실패했습니다. {e}")
audio_stream = None
print(e)
if audio_stream:
selected_language_name = selected_language.split("/")[0] # Swedish/sv-SE -> Swedish
st.download_button(
label="Download MP3",
data=audio_stream,
file_name=f"ai_voice_{selected_language_name}_{selected_engine}_{selected_person_name}.mp3",
mime="audio/mpeg",
disabled=False if audio_stream else True,
)
st.audio(audio_stream, format="audio/mpeg")
else:
st.warning("내용을 입력해주세요.")
print("no")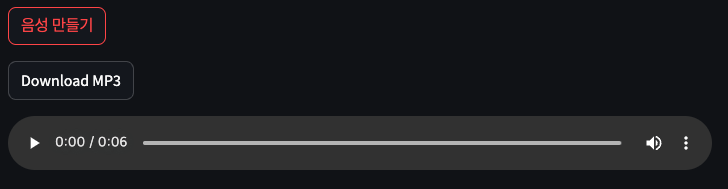
텍스트 언어에 맞는 언어와 목소리를 선택해야 멀쩡하게 잘 만들어져요!
만들어진 목소리는 아래와 같이 만들어져요.
완성된 코드는 아래와 같고 github에서도 볼 수 있어요.
import streamlit as st
from helper.ai_voice_helper import AIVoiceHelper
from helper.voices_dictionary import voices_dict
voice_dict = voices_dict.copy()
language_list = voice_dict.keys()
st.set_page_config(
page_title="AI 음성 만들기 with AWS Polly",
page_icon="🎤",
)
st.title("AI 음성 만들기")
st.markdown(
"""
AI 음성을 만들어 보세요.
### 사용법
1. 언어를 선택 합니다.
2. 엔진을 선택 합니다.
- neural 엔진 : 표준 음성보다 더 높은 품질의 음성을 생성할 수 있습니다. NTTS 시스템은 가능한 가장 자연스럽고 인간과 유사한 텍스트 음성 변환을 제공합니다.
- standard 엔진 : 표준 TTS 음성은 연결합성(concatenative synthesis)을 사용합니다. 이 방법은 녹음된 음성의 음운을 연결하여 매우 자연스러운 합성 음성을 생성합니다. 그러나 불가피한 음성 변화와 음파를 분할하는 기술적인 한계로 인해 음성의 품질이 제한됩니다.
3. 목소리를 선택 합니다.
4. 속도를 선택 합니다.
</br>
""",
unsafe_allow_html=True
)
with st.sidebar:
access_key = st.text_input(
"Write down a AWS ACCESS KEY",
placeholder="AWS ACCESS KEY",
)
secret_access_key = st.text_input(
"Write down a AWS SECRET ACCESS KEY",
placeholder="AWS SECRET ACCESS KEY",
)
selected_language = st.selectbox("언어 선택", language_list)
selected_engine = st.selectbox("엔진 선택", voice_dict[selected_language].keys())
select_data_list = [item['select_data'] for item in voice_dict[selected_language][selected_engine]]
selected_data = st.selectbox("목소리 선택", select_data_list)
selected_person_name = selected_data.split(" / ")[0] # "Lupe / Female / Bilingual" -> "Lupe"
st.markdown(
"""
### 속도 선택
- 20% : 매우 느림
- 50% : 느림
- 100% : 표준
- 150% : 빠름
- 200% : 매우 빠름
""",
unsafe_allow_html=True
)
speed_rate = st.slider(
label="속도 선택",
min_value=20, max_value=200, value=100,
help="전체적으로 적용할 속도를 선택합니다. ssml 태그를 사용하면 부분적으로 속도를 따로 적용할 수 있습니다.",
)
text = st.text_area(
label="내용 입력",
help='음성으로 변환할 내용을 입력해주세요.',
placeholder='음성으로 변환할 내용을 입력해주세요.',
height=500,
)
create = st.button(
label="음성 만들기",
)
if create:
if selected_person_name and text:
try:
audio_stream = AIVoiceHelper(
service="polly",
access_key=access_key,
secret_access_key=secret_access_key,
).synthesize_voice(
text=text,
voice_id=selected_person_name,
rate=speed_rate,
engine=selected_engine,
)
except Exception as e:
st.error(f"음성 변환에 실패했습니다. {e}")
audio_stream = None
print(e)
if audio_stream:
selected_language_name = selected_language.split("/")[0] # Swedish/sv-SE -> Swedish
st.download_button(
label="Download MP3",
data=audio_stream,
file_name=f"ai_voice_{selected_language_name}_{selected_engine}_{selected_person_name}.mp3",
mime="audio/mpeg",
disabled=False if audio_stream else True,
)
st.audio(audio_stream, format="audio/mpeg")
else:
st.warning("내용을 입력해주세요.")
print("no")
st.markdown(
"""
### FAQ
1. 음성 변환 실패 사례 (voice id 에러)
- [AWS Polly 음성 목록](https://docs.aws.amazon.com/ko_kr/polly/latest/dg/voicelist.html) 에서 사용 가능한 목소리를 확인해주세요.
- 만약 목소리가 없다면, helper/voice_dictionary.py 에서 해당 목소리를 삭제 해주세요. (aws 에서 지원 종료 했을 경우)
"""
)
# 개선 사항
현재는 인풋 창으로 일회성으로 AWS key 들을 받기 때문에 streamlit 프로젝트 내 다른 페이지로 넘어가면 입력 값이 사라지는 이슈가 있는데요, 이는 streamlit 이 요소에 변화가 있을 때마다 페이지를 새로 불러오기 때문에 발생하는 이슈예요.
이를 해결하기 위해선 streamlit에서 제공하는 session에 값을 저장해 놓거나, 로컬 프로젝트로만 사용한다면 로컬에 파일 형태로 데이터를 저장하여, 사용 시마다 불러와서 사용하는 방법이 있어요.
만약 프로덕션 레벨로 프로젝트를 배포한다면 로그인을 제공하고 key 들을 암호화해서 저장하는 방법도 있긴 한데, 아직 이 정도의 프로젝트를 위해 로그인 등을 구현해야 할까 라는 생각이 있어 아직 진행은 하지 않았어요.
그리고 각 값들을 상수 화하여 받게 할 수 있어요. 예를 들어 엔진이나 서비스 변수들은 class enum으로 만들어 상수를 넘기도록 할 수 있어요.
이 내용들은 프로젝트를 더 디벨롭할 때 적용하기로 해요.
AWS polly 사용량을 조회하는 화면도 만들긴 했는데, 궁금하신 분 있으면 추가로 글 작성해서 올려볼게요!
이 외 궁금한 거 있으면 댓글 남겨주세요 :)